Pycharmを使ってStreamlitでWEBアプリを開発する際にDebugする方法
結論から言うと、答えはここに書いてありました。
stackoverflow.com
見つけるのに苦労したわ。
もともとstreamlitの公式ページで探していて、そこにコメントがあったのが見つけたきっかけ。
ChatGPTは使い物にならなかったわ。
discuss.streamlit.io
ポイントはデバッグ対象のプログラムそのものではなく、streamlitをデバッグ対象にするってところだと思う。
VS Codeでデバッグする方法はググると沢山出てきて、例えば、これを見れば良さそう。
qiita.com
いっそ、IDEをVS Codeに戻そうかと思ったけど、安直な考えはやめて調べて良かったw。
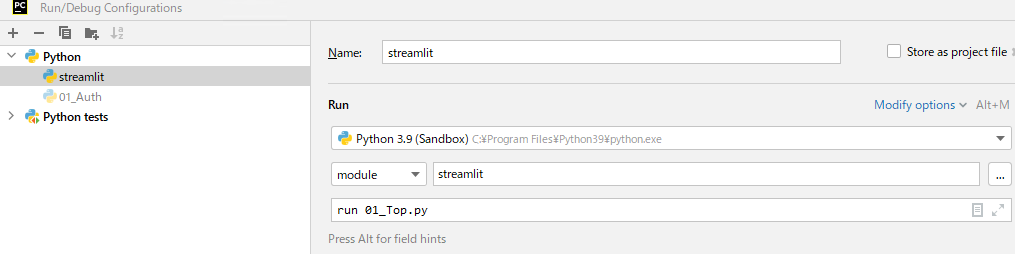
例えば、01_Top.pyという画面がエントリーポイントのWEBをデバッグしたい場合は、次のように設定して成功した。
Gitメモ
こういう単純なコマンドは、いつまで経っても覚えていられない。
- ローカルブランチの確認
$ git branch
- ローカルブランチ変更
$ git checkout [ブランチ名]
- 現在のブランチの確認
$ git branch -a
- 過去の特定のコミットからブランチを作成する方法
$ git checkout <リビジョン番号> -b 新規ブランチ名
$ git status #ファイルの編集状態確認
$ git add . #コミットしたいファイルの追加
$ git commit - m "コミットコメント"
$ git push origin ブランチ名
これだと確かに作成されたが、特定のコミット以前の履歴も新規ブランチに残ったんだよなぁ。でも、Googleで検索すると、このやり方しか出てこないのが納得できない。
Microsoft PowerAutomate(旧Microsoft flow)で使用する関数
全然頭に入ってこない上に、情報が少ないからすごく使いづらい。。。
大嫌い。
日付別のフォルダ作成関数
concat('/',formatDateTime(addhours(utcnow(),9),'yyyy-MM-dd'))
PowerShellで1月から12月までのフォルダを01、02、・・・、11、12というようにワンライナーで作成する
フォルダを作成したい場所に移動して、次を実行。
PS C:\tmp> New-Item (1..12 | % { "{0:00}" -f $_} ) -ItemType Directory|PowerShell、使ってこなかったしあまり使わないからすぐに忘れる~。
SSHでGoogle Authenticatorを利用する場合、Tera Termでは自動ログインできない ~ /ask4passwdの指定で自動ログインを回避
普段、TeraTermはショートカットを作成して、プロパティにコマンドを書いている。
例えば次のように。
"teratermインストールフォルダ\ttermpro.exe" 接続先IP:ポート番号 /auth=publickey /user=ログインユーザ名 /keyfile=秘密鍵ファイル
これで自動ログイン可能。
ところが、SSHにGoogle Authenticatorを適用し、公開鍵ではなく、パスワードとAuthenticator Codeを入力してログインしようとすると、ログインに失敗する。
コード入力画面が表示されない。
そこで、次のblogを参考にして、自動ログインをしないようにしたところ成功。
https://ttssh2.osdn.jp/manual/4/ja/commandline/ttssh.html
"teratermインストールフォルダ\ttermpro.exe" 接続先IP:ポート番号 /ask4passwd /auth=keyboard-interactive /user=ログインユーザ名
Amazon LinuxでGoogle Authenticatorを利用したいがインストールに失敗する ~ No package google-authenticator available.
例えば、下記blogで紹介されているように簡単にインストール出来るように思われたが・・・。
blog.apar.jp
[root@host ~]# yum install google-authenticator ・・・・・ No package google-authenticator available. Error: Nothing to do
sudo yum install epel-releaseでEPELリポジトリをインストールしようとしても同様にNo package available。
しかし、下記のようにURLから直接rpmを指定するとEPELリポジトリを無事インストールできた。
[root@host ~]# yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
goofysでAWS S3をmountしたディレクトリが権限不足で見れなくなる
これはハマった。
AWS EC2のディレクトリをgoofysでmountしてS3と繋いだ瞬間に、権限エラーでアクセスできなくなった。
他サービスとの連携をテストしていて、mountしただけでテストに失敗。たちが悪いのが、シェルで権限確認しても変化がなかったこと。
ls -ltrで確認していたのだが、所有者も権限情報も変わらずroot、777だった。。。
そこでググると対応方法判明。
「-o allow_other」オプションを付与して実行すればよい。
goofys -o allow_other
知らんがな。。。
このblogに書いてありました。
www.ytyng.com
ちなみに、「--dir-mode 0666 --file-mode 0666」でdirモードとfileモードを指定。